
WoW world model generates high-quality, physically consistent robot action videos in Out-of-Distribution (OOD) scenarios, enabling closed-loop corrections and real-world robotic execution. The illustration shows the model's strong generalization across diverse tasks and environments.
World models have recently emerged as a powerful paradigm for robotics, integrating perception, action, and reasoning. However, most existing world models focus on narrow domains or rely heavily on simulation, limiting their ability to generalize to real-world embodied interaction. We introduce WoW (Harnessing Intuitive Physics from a Scalable Embodied World Model), a large-scale embodied world model designed to capture intuitive physics and enable scalable robot learning. WoW unifies multimodal inputs from diverse real and simulated datasets, and leverages embodied interaction to learn dynamics that transfer robustly across environments and robot platforms. Across extensive experiments, WoW demonstrates strong generalization in manipulation and long-horizon planning, enabling closed-loop control and real-world deployment. Our results highlight that embodied interaction and large-scale training are critical to building world-omniscient models for robotics.
Physics Understanding: WoW demonstrates sophisticated understanding of physical properties including object splitting, deformation, lighting effects, adhesion, and counterfactual reasoning.
Robot Manipulation: Diverse manipulation tasks including cube stacking, rope and cloth handling, kitchen operations, conditional reasoning tasks, object cutting, desk organization, and long-horizon planning scenarios.
Real-world Scenarios: Natural environments and daily life activities including kitchen scenes, workplace tasks, and everyday interactions demonstrating practical applicability.
Object Dynamics: A diverse collection of cube interactions showcasing different physical behaviors, collision dynamics, and environmental responses.
Artistic Interaction: WoW demonstrates understanding of 2D-3D relationships by enabling robotic hands to extract objects from famous paintings, showcasing cross-modal reasoning between visual art and physical manipulation.
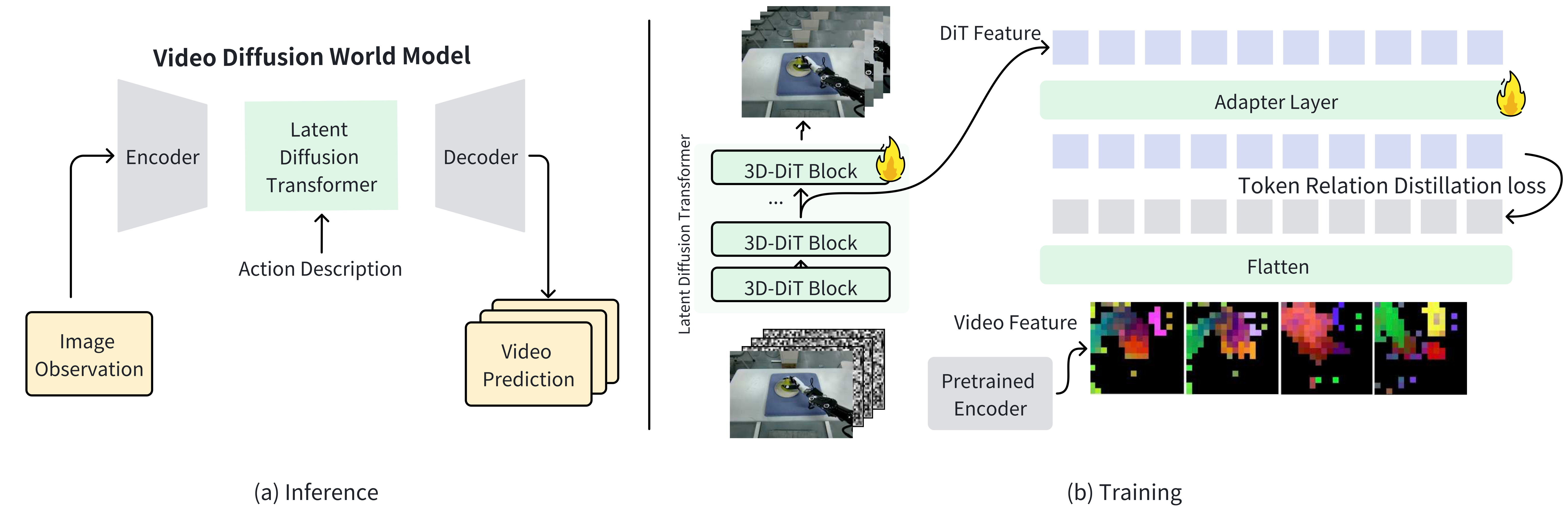
Model Overview
(a) Inference: a latent diffusion transformer predicts future frames from image observations and text-based action descriptions. (b) Training: DINO features supervise intermediate DiT representations via a token relation distillation loss to improve spatial-temporal modeling.

Scaling Law Comparison at Varying Data Scales. Performance comparison across four different dataset sizes (30k, 200k, 600k, 2M samples) on multiple benchmarks, demonstrating clear improvements with increased training data following established neural scaling laws.
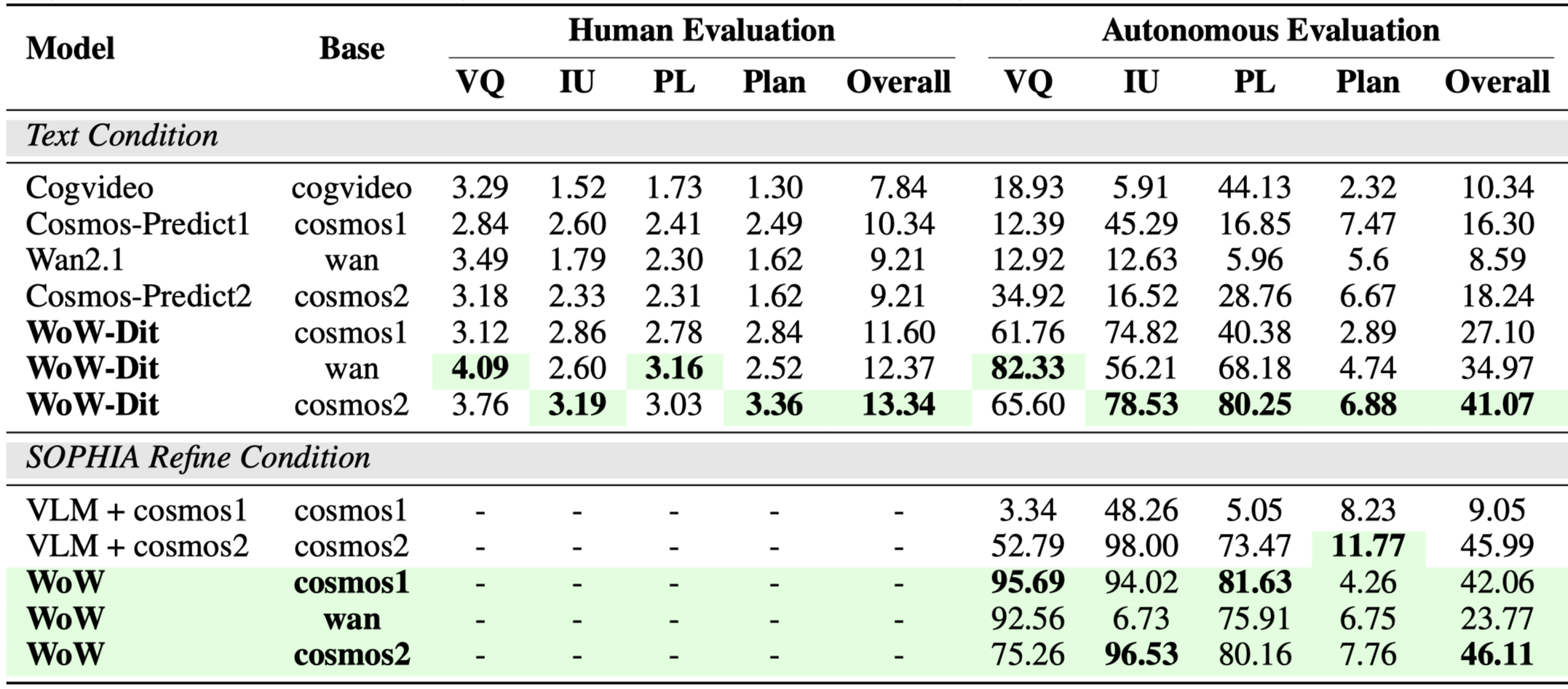
Comparative Analysis Across Video Generation Models. Comprehensive evaluation of different models including CogVideoX, Cosmos-Predict, Wan2.1, and our proposed WoW across multiple metrics: Video Quality (VQ), Instruction Understanding (IU), Physical Law (PL), and Planning. Results show both human evaluation and autonomous evaluation scores, with WoW achieving superior performance across most dimensions.
@article{anonymous2025wow,
author = {Anonymous},
title = {WoW: Harnessing Intuitive Physics from a Scalable Embodied World Model},
journal = {ICLR 2026 Submission},
year = {2026},
note = {Under Review}
}